哈喽,我们这节课开始介绍一下关于redis的内容,为啥要学这个呢,咱也不说虚的,那些很多说为了让自己技术更全面,为了让自己更优秀,为了让自己效率更高,都是狗屁,我学习一门技术的理由很简单,只是为了找工作时或者在职场上能少一个被直接淘汰的理由。
概述
那么既然我们学习redis,又到了最开始那个千篇一律的问题了,redis是个什么东西?说实话我已经不喜欢回答这种问题了,他爱是什么东西是什么东西,他是什么东西你真的感兴趣吗?你真的关心吗?你真的在乎吗?不,你在乎的只有你自己。
所以说我也懒得说这个是什么东西,反正就是一种技术产物。而这种技术我们称之为NoSQL。
可能又有人要问,NoSQL又是什么呀?这是为了解决性能问题而产生的一种技术。现在告诉你了,你学会了吗?知道怎么用吗?你说你闲得那么好奇干什么啊?知道这个玩意儿是什么有什么用啊?以后这些类似的事少打听。
背景
行了,那么我们看看为什么会有这种技术吧。
在最初的时候,也就是所谓的web 1.0时代,一个简单的web项目架构也是很简单。
那个时候吧车马很慢,网速比车马还要慢,但是渐渐到了所谓的web 2.0时代,随着网络技术的发展,智能手机的普及,3G,4G的到来,网速也提升了,渐渐的web服务器的吞吐量也就大了起来。那么如果还是用之前的架构会怎么样呢?
如果在大量访问量的情况下,依然使用旧的架构就会对web服务器造成CUP压力,对数据库服务器也会造成很严重的IO压力。
解决CUP压力
面对老旧架构逐渐无法满足市场需求,就好像火车站排队买票,如果说只有一个售票口的话,那么售票压力就会很大,可能会存在很多人还没来得及买到票,他想买的那个班次就已经开走了。但是活人还能让尿憋死?首先我们来解决一下CPU压力,现在市面上最主流的方式便是服务器集群。简单的来说就是用反向代理服务器配上负载均衡:
像上面这种架构的话当我们利用负载均衡将所有的请求都分发给服务器集群中的各个服务器,这就好比还是火车站排队买票,我们这次开放 10 个售票口,那么售票压力就会减小很多。
但是虽然解决了服务器CUP压力,又出了新的问题。学习过前端的都知道,就是session问题,因为session是存储在服务器上的。那么就会出现什么情况呢,第一次用户登录时,请求被分发到了服务器 1,那么session就会存储在服务器 1 上面的。那么第二次再访问这个网站的时候,负载均衡不一定可以将这请求依旧分发给服务器 1。那么这下就没法在服务器上面获取到session。
就好比大学城里有 5 个健身房,大学城的学生太多了,因为第一个健身房人少,所以你去了第一个健身房,然后办了卡。第二天你再去健身房,发现只有第二个健身房人少,那么你去第二个健身房肯定是没有办法查询到你的会员记录的。
可是这个问题又应该怎么解决呢?
解决session问题
其实解决session问题是有很多方法的。
比如我们可以将session存储在cookies中,每次发送请求的话,可以直接通过cookies携带用户信息去请求服务器。但cookies是存储在浏览器中的。所以说安全性就会比较低了,如果有其他人在电脑上获取到了用户信息,那么这将是一件很危险的事。
就好像有人拿到了你的银行卡,密码和身份证一样,那问题可就严重了诶,这样别人就会知道你居然这么穷,多可怕。
那么我们可以不存在cookies中,我们依然将session存储在服务器端,那么我们把session复制下来在每个服务器都存一份,就好像你在每个健身房都办一张卡,那么不管你去哪个健身房都有会员。
但是这样的话又有一个新的问题session数据冗余,造成了大量空间资源浪费。好比你办了那么多健身房的会员卡,那么你指什么吃啊?钱都拿去办卡了,你吃什么?你办了卡又不一定会去健身房,只能慢慢等卡过期,那么你的钱是不是都被你给浪费了?
当然了,我们可以选择将session存储在数据库中,或者存储在文件服务器中。那这样的话就不会造成数据冗余了啊。这就有点类似于连锁店,你办了卡,所有分店都能用。
但是呢这个方案是要操作IO的,所以会出现IO效率问题。这个在我们现实生活中的连锁店中可是没有出现过。
那么我们最终还是来到了这一步。那就是存储在NoSQL数据库中。
这种架构看着没有什么问题,但是为什么用NoSQL数据库就不会出现IO效率问题呢?因为NoSQL数据库是将数据存储在内存中的,数据查询并不需要交互IO,这样的话速度快,而且数据结构简单,就可以解决掉性能问题,而没有什么明显的弊端。
解决数据库IO问题
通常我们日常开发中用的数据库基本上都是关系型数据库居多,比如MySQL,Oracle,db2等,但是这些数据库是将数据存储在磁盘中的,在进行操作的时候都要进行IO的交互,当数据量小的时候我们进行IO交互是没有问题的,效率也很高。
但是随着项目的发展,用户的增多,数据量也会越来越大,那么在这个时候我们再操作数据库与IO进行交互的话就会很明显地感觉到效率降低了。那么我们该怎么做呢,通常来说我们会选择将库还有表来进行拆分,这样的话是可以解决IO压力的,但是这个方法也是有弊端的,拆分库和表,注定就会要牺牲掉一部分的业务逻辑。
当然除了这个方法我们也可以将表根据具体业务逻辑选择行存储或者列存储。那么是什么意思呢?比如说:
id |
name |
age |
gender |
phone |
|---|---|---|---|---|
| 1 | 张三 | 20 | 男 | 159 0000 0000 |
| 2 | 李四 | 21 | 男 | 158 1111 1111 |
| 3 | 王五 | 22 | 男 | 157 2222 2222 |
想这样一张表,这是一个很常见的关系型数据库的表。所谓的行存储就我们以每一行的数据作为一个存储单元,像传统的关系型数据库,例如MySQL,Oracle等等基本都是行存储
id字段来查询到id为 2 的数据。但是这个架构的弊端就是当数据量很大的时候,比如表里有 100 万条数据,那么我们想要计算这 100 万条数据的平均年龄,那么我们再来查询,效率就很很低。
随着大数据时代的到来,Hbase,EMC Greenplum等数据库渐渐兴起,这些都是列存储的数据库,这些就是将上面的表中每一列作为一个存储单元。
id来查询出id为 2 的这一行数据,效率就会很低。
所以说行存储和列存储,可以根据具体的业务逻辑来具体选择,从而来减轻IO的压力。
但是行存储和列存储终究还是太麻烦了,有没有其他的方案了呢?当然还是有的,我们可以用NoSQL做缓存数据库
我们这样,将一些高频查询的数据存储在NoSQL中,用NoSQL数据库来作为网站的缓存,这样的话即便有大量的用户,大量的数据,大量的请求,我们也可以通过缓存数据库来降低数据库服务器的IO压力。
NoSQL
那么说了这么多了,我们好像并不怎么了解NoSQL,因为我让你们少打听。但是我会在合适的时候告诉你应该告诉你的东西。比如我现在会告诉你,NoSQL是一种非关系型数据库,不依赖业务逻辑,以简单的key-value的模式存储,大大提高了数据库的扩展能力。
那么什么是所谓的key-value存储模式呢?举个例子,大家在公司都有自己的工号,在公司的信息系统中,只要输入你的工号,就会查询出你的员工信息,而这个工号就是key,而员工信息就是value,每个人的工号和其员工信息是一一对应的。key-value模式也是这样,一个key只对应一个value,我们可以通过key来得到与之对应的value。
那么NoSQL还有什么特点呢?
首先NoSQL不遵循SQL的标准,我们用SQL来操作数据库的话要用复杂的SQL语句来完成一系列操作。但是NoSQL不用,NoSQL只需要用相应的命令就可以了。仿佛似面向过程与面向对象的区别。
另外NoSQL不支持事务的原子性,一致性,持久性和隔离性,这个暂时不做过多介绍,在后续的学习中大家慢慢去体会。至于对这四个特性不了解的朋友,大家可以去认真查阅关系型数据库的的事务相关的资料。
最后一个特点也是我们最重要的,就是NoSQL的性能远超SQL,不然的话我们引入NoSQL就没有意义了。但是为什么呢?因为NoSQL的数据是存储在内存中的。计算机对内存的读写操作可是远超对硬盘的读写操作的。所以说NoSQL的性能要远超SQL的
NoSQL的适用性
那么我们介绍了NoSQL了。知道这个对象是用来解决性能问题的,那么我们还要用关系型数据库干什么?直接都用NoSQL不就得了嘛,其实并不是我们想当然的这样。NoSQL也是有自己的适用场景的。
就好像我们要进行数据高并发的读写的话,比如电商秒杀啊,12306 春运抢票啊,再比如大数据海量数据的读写啊,或咋要求数据库有高扩展性啊,这种都可以使用NoSQL。
但是如果我们想要利用数据库的事务,以及即席查询的话,那么NoSQL就不太适用了,倒不是说NoSQL不支持事务,NoSQL是不支持事务的四大特性。当我们需要事务支持的话通常还是会选用关系型数据库的。至于什么是即席查询。简单来说就是自定义性和灵活性都很强的查询就叫即席查询。
所以说我们是要根据相应的业务场景来定是否使用NoSQL。
redis简介与安装
首先来说redis是NoSQL数据库的一种,目前来说在市面上其实是非常活的,最常用的NoSQL数据库中redis算是排在前几名的。在redis之前,大家用一个叫做MemCache的NoSQL数据库,但这个数据库有一个缺点,就是不支持把数据持久化到硬盘中去,只能存在内存里,那么万一服务器一关机,那么数据就都丢了啊。
后来redis出现了,redis几乎涵盖了memcache所有功能,最关键的一点,redis支持将数据持久化到硬盘中去。
那么redis都有什么特点呢?
首先和所有NoSQL数据库一样,数据存储在内存中,而且是key-value模式。而且redis的数据都是原子性的,而且都支持push/pop、add/remove以及取交集并集等丰富的操作,另外redis还支持不同方式的排序,支持将数据持久化到硬盘中,而且redis还会周期性地自动将数据写入硬盘,redis还有一个特点就是实现了主从同步,至于这个是什么,后期的学习中会慢慢介绍。
除此之外,redis采用的是单线程 + 多路IO复用的技术从而来实现类似于多线程的操作。什么意思呢?
比如你去买周杰伦演唱会门票,但是你觉得你肯定买不到啊,那么火哪是那么容易买的啊,那么你就去找黄牛买票。你就去找了一个黄牛帮你买票,因为你只找了一个黄牛,那么这个就是所谓的单线程,但是这个黄牛并不是只接了你一个人的单子啊,也许他还接了张三买德云社演出票的单子,又接了李四买脱口秀大会演出票的单子。但是你们让黄牛帮忙买票了,黄牛就一定能买到吗?是不是不一定啊?但是在他买到票之前,你们总不至于一直陪着黄牛在哪等吧,你们肯定还是该干嘛干嘛去,等黄牛买到票了,再来通知你们。这就是所谓的多路IO复用,单线程做多件事,但是事情完成之前有不影响其他的事情,从而实现类似于多线程的效果。
安装redis
我们介绍完了redis的特点之后,那么我们准备学习吧,在学习这个数据库之前,我们要做的就是先安装这个数据库,通常来说redis我们都在Linux系统上安装的比较多,所以我们也就只介绍Linux环境下安装redis。
其实很简单,直接用包管理工具也就可以了,拿CentOS系统为例,首先执行命令添加EPEL仓库
sudo yum install epel-release sudo yum update
添加完仓库之后更新源,然后执行命令
sudo yum install redis
然后就等待安装完成就可以了。
启动redis与简单使用
Linux系统启动redis也是很简单的,我们通常都以服务的方式来启动redis
sudo systemctl start redis
我们可以方便快捷地使用systemctl工具来进行服务的管理。
启动了redis服务之后,我们通过redis-cli命令来进入redis交互界面。
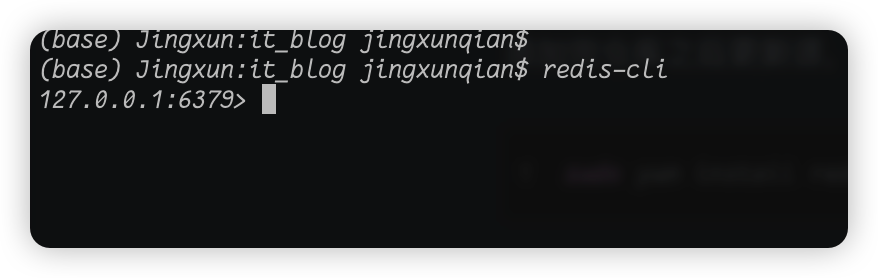
我们看当我输入了redis-cli然后敲下回车就会进入一个新的交互界面,在这个界面就可以通过redis的命令来对redis进行操作
比如我们先来测试一下连通性,执行命令ping
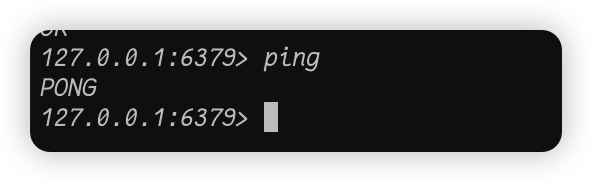
我们执行了ping命令之后,如果像图中那样输出了PONG,那么说明我们已经连接成功了。可能有人要问了,还会有进入交互界面但是连接不成功的情况吗?当然有:
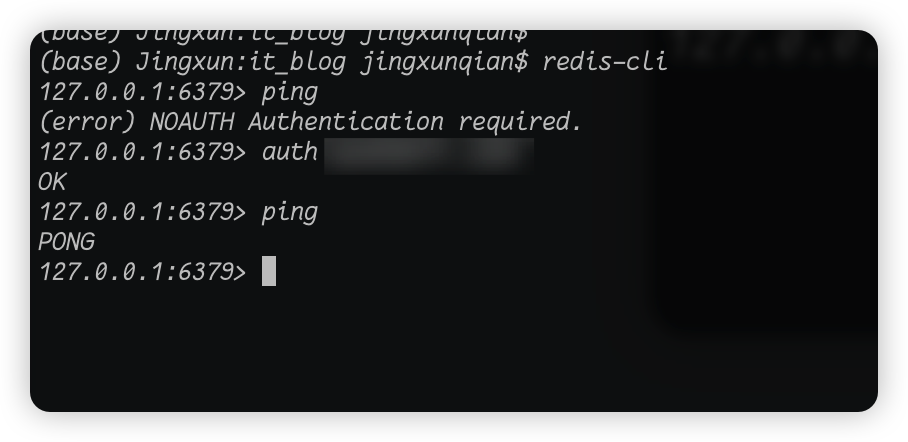
我们来看上面这张图,我们第一次ping的时候就报错了,说明没连接成功,然后我们执行了auth命令之后再ping就成功了,这是为什么呢?因为我本地的redis设置了密码,auth后面我打了马赛克的那一段就是密码,只有我验证了密码之后才能成功连接上数据库。至于怎么给redis设置密码,我们后面会介绍。
那么我们现在安装好了redis,也学会了启动redis,也知道怎么在命令行里面连接redis了,那么我们来说几个基础知识点:
第一,redis的默认端口号是 6379,没有为什么,记住就行了,知道为什么也没有意义。而且我们后续会介绍如何修改redis占用的端口号,只需要知道默认端口号是 6379 就行了
第二,redis默认提供 16 个数据库,和数组的索引类似,这 16 个库的编号从 0 开始,当我们连接上redis时默认使用的是 0 号数据库。
第三,我们可以通过select命令加数据库编号来切换数据库,命令不需要区分大小写

我们从图上可以看到,一旦我们切换了数据库就会显示数据库的编号,但是切换回默认数据库的话则会省略数据库编号。
这两个知识点就作为一个常识来了解就好,并不用去深究,redis是NoSQL数据库,NoSQL的存储方式是key-value,而我们都是通过key来关联到value,那么直白地来看,NoSQL就是对key来玩一些花样啊。没错,那么我们来看看key都有哪些基础的花样可以玩:
首先,keys *命令,这个命令是用来查看当前库都有哪些key:
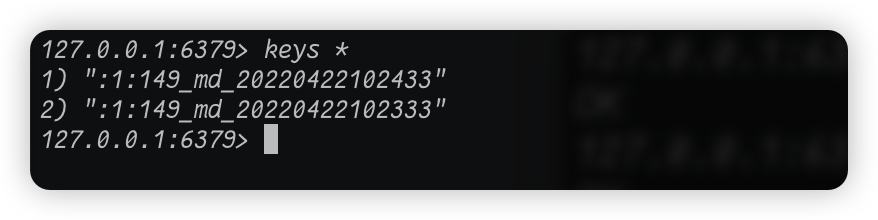
这个是我的一个web项目存进来的缓存,我先把这些给清掉
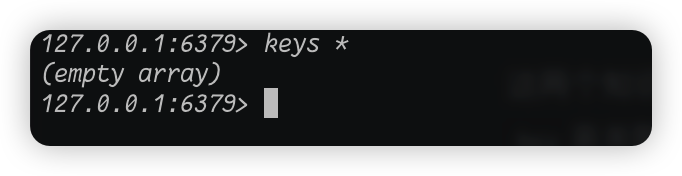
清掉之后我们看见当前库里面是空的,一个key都没有。那么我们就可以引出新的命令了:
set命令,这个命令是向库里添加一个key:
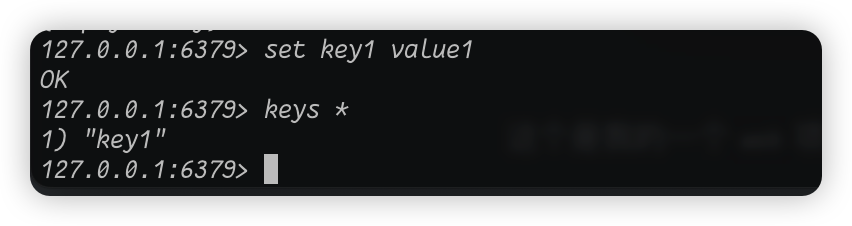
我们来看上面这张图,我们set命令有两个必须传入的参数,用空格隔开,第一个参数就是key的名称,随便取,另一个是value的值,这个值可以是redis所支持的数据类型的任何一种。至于数据类型我们后续的学习中会介绍。那么我们执行的命令set key1 value1做了什么呢?其实就是想当前库里添加一个叫做key1的key,而这个key对应的value值是value1。现在我们再执行keys *,就会看见库里现在有一个叫key1的key。
既然我们能添加key,自然少不了删改这个key,众所周知,对数据库的操作无非就是增删改查这四个字,我们可以用set增,那么改呢?其实改也是set:

就如同图中一样,直接用set命令重新新增key1,这个时候并不会在库里新增一个新的key1,而是用这次set的value覆盖掉库里原有的key1所对应的值,那么我们怎么验证呢?这就要提到对数据库的查询操作了,怎么查呢?
与set对应的就是get,没错,我们可以用get命令加上key的名称来查看指定的key对应的value:

我们从图中可以看见第一次我们get key1获取到的value的值是value1,然后我们重新set了key1,再来执行get key1得到的就是第二是重新set时候的value的值
那么到这一步redis的增改查都介绍完了,那么怎么删呢?这样我们就引出了del命令和unlink命令,这两个命令都可以删除一个key,比如我们先用del:
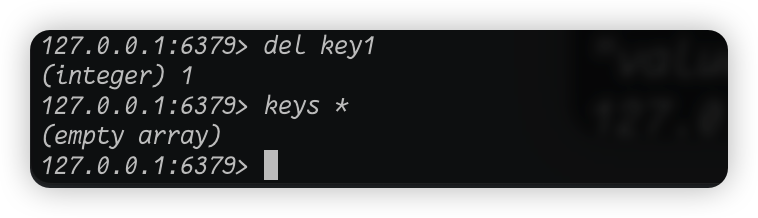
我们看见执行完del命令之后,库里已经没有任何key了,但是执行del命令的时候输出了一个数字 1 是什么意思呢?我们都知道计算机是二进制的,只有 0 和 1,那么 0 和 1 所能表示的东西就多了,但是其中最常见的之一就是用 1 表示成功,用 0 表示失败。我们现在已经清空了当前库了,库里也没有key了,那么我这个时候再执行del命令,按照我们刚才的逻辑是不是应该输出 0 才对?因为没有key了,那么不可能删除成功的,所以按照逻辑上来说应该输出 0,那么我们来验证一下:
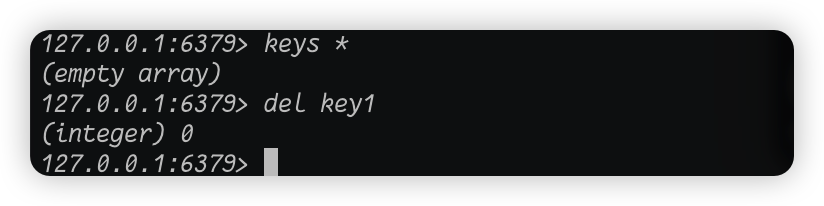
果然如我们预期一样,我们输出的是 0。所以说执行del命令输出的数字代表着这个key是否成功删除。那么我们再来看看unlink命令:
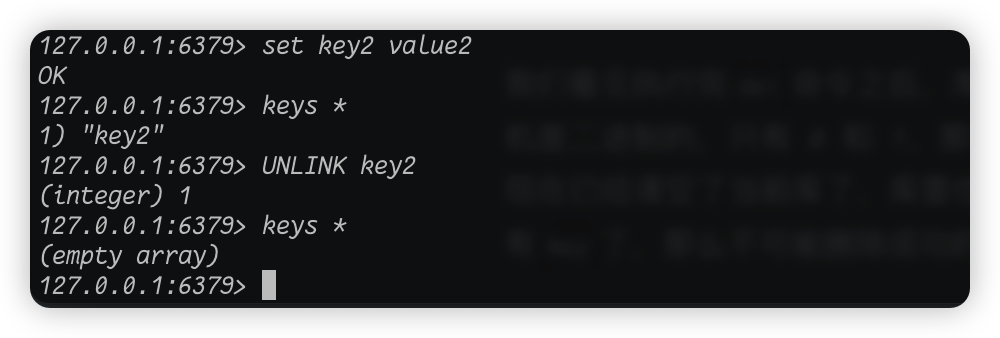
我们先是新增一个key,然后用unlink命令删除,我们看见,执行unlink命令输出的也是数字 1,和del命令一样,这个数字也代表是否成功删除了。
但是del命令和unlink命令有什么区别呢?其中del命令是直接删除,而unlink命令只是将key从keyspace里面 删除,但是数据实际上并没有删除,而unlink真正删除数据的步骤实在后续的异步任务中操作的。当然这个问题我们后续会详细介绍,这里就不再赘述了。
当然了,我们说完了增删改查,还有其他的命令要说,比如exists命令,这个命令可以用来判断某个key是不是存在于当前的库:
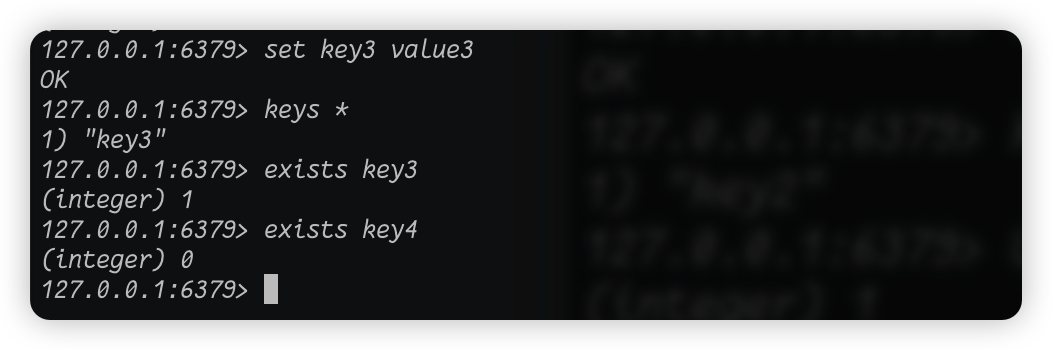
我们set一个新的key,我们看见,当前的库里面只有这一个key,那么我们执行exists命令,输出的也是数字来表示是否存在。
另外还有type命令,从命令字面意思上就可以看出,这是个查询类型的命令type命令后面跟key的名称,这里不在赘述了。
另外还有两个命令expire和ttl命令这两个命令一个是给key设定过期时间,另一个是查询key还有多长时间过期,时间以秒为单位。
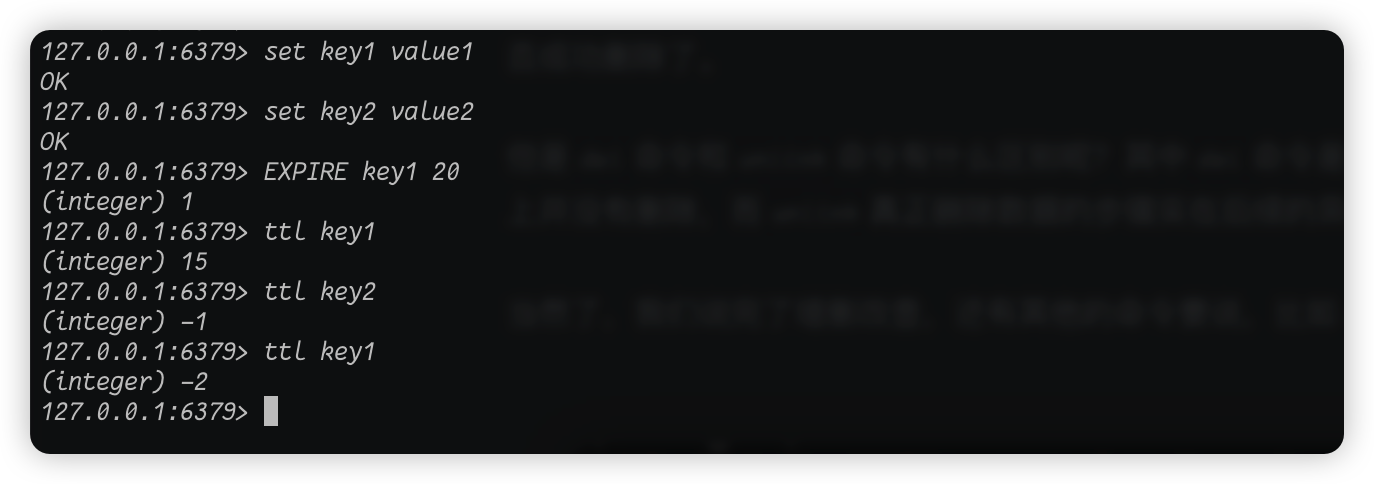
我们set两个key,其中key1我们设置 20 秒的过期时间,key2不设置过期时间,也就代表key2永不过期。我们看,expire输出也是数字,代表设置是否成功。然后用ttl命令查询key1还剩多少时间过去,输出了 15,说明还剩 15 秒就会过期。然后我们又用ttl命令查了一下key到底过期时间,输出是 -1,但是大家想也知道在我们这个宇宙和维度中,时间是不可能有负数的,那么这里的 -1 肯定有别的意思,没错,这里的 -1 代表的是永不过期。等时间差不多了,key1应该已经过期了,再用ttl命令来查一下key1的过期时间,输出了 -2,那么这里的 -2 又代表什么呢?这里的 -2 就代表已经过期了。
总结
以上便是这节课的内容,我们来简单做一个总结:
NoSQL是一种为了解决性能问题而诞生的技术NoSQL可以解决服务器集群的session问题NoSQL可以做缓存数据库来缓解数据库服务器的IO压力NoSQL采用的是key-value的存储模式,不遵循SQL标准,不支持事务四大特性,数据存储在内存中,性能远超SQLredis采用单线程 + 多路IO复用实现类似多线程的效果redis实现了主从同步
Copyright statement:The articles of this site are all original if there is no special explanation, indicate the source please when you reprint.
Link of this article:https://work.lynchow.com/article/redis-introduction/

